Tl;dr: A common challenge with distributed systems is how to ensure that state remains synchronized across systems. At Coinbase, this is an important problem for us as many transactions flow through our microservices every day and we need to ensure that these systems agree on a given transaction. In this blog post, we’ll deep-dive into Overseer, the system Coinbase created to provide us with the ability to perform real-time reconciliation.

By Cedric Cordenier, Senior Software Engineer
Every day, transactions are processed by Coinbase’s payments infrastructure. Processing each of these transactions successfully means completing a complex workflow involving multiple microservices. These microservices range from “front-office” services, such as the product frontend and backend, to “back-office” services such as our internal ledger, to the systems responsible for interacting with our banking partners or executing the transaction on chain.
All of the systems involved in processing a transaction store some state relating to it, and we need to ensure that they agree on what happened to the transaction. To solve this coordination problem, we use orchestration engines like Cadence and techniques such as retries and idempotency to ensure that the transactions are eventually executed correctly.
Despite this effort, the systems occasionally disagree on what happened, preventing the transaction from completing. The causes of this blockage are varied, ranging from bugs to outages affecting the systems involved in processing. Historically, unblocking these transactions has involved significant operational toil, and our infrastructure to tackle this problem has been imperfect.
In particular, our systems have lacked an exhaustive and immutable record of all of the actions taken when processing a transaction, including actions taken during incident remediation, and been unable to verify the consistency of a transaction holistically across the entire range of systems involved in real time. Our existing process relied on ETL pipelines which meant delays of up to 24 hours to be able to access recent transaction data.
To solve this problem, we created Overseer, a system to perform near real-time reconciliation of distributed systems. Overseer has been designed with the following in mind:
- Extensibility: Writing a new check is as simple as writing a function, and adding a new data source is a matter of configuration in the average case. This makes it easy for new teams to onboard checks onto the platform that is Overseer.
- Scalability: As of today, our internal metrics show that Overseer is capable of handling more than 30k messages per second.
- Accuracy: Overseer travels through time and intelligently delays running a check for a short time to compensate for delays in receiving data, thus reducing the number of false negatives.
- Near real-time: Overseer has a time to detect (TTD) of less than 1 minute on average.
Architecture
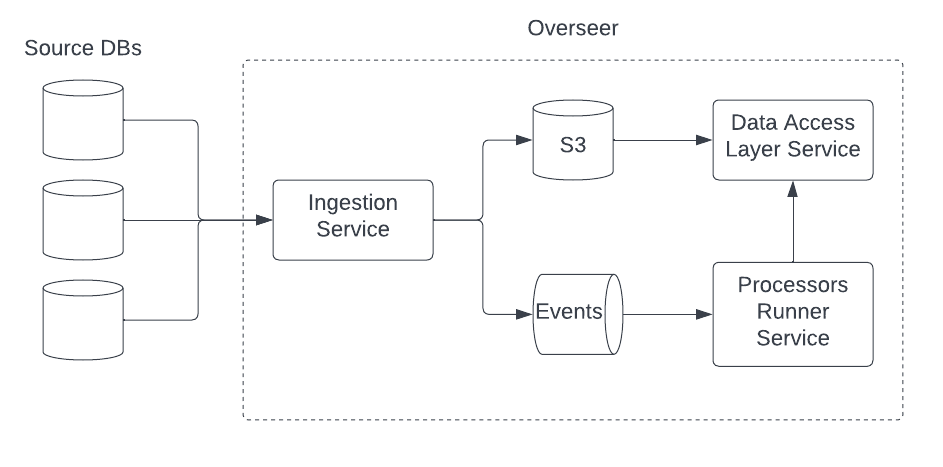
At a high-level, the architecture of Overseer consists of the three services pictured above:
- The ingestion service is how any new data enters Overseer. The service is responsible for receiving update notifications from the databases which Overseer is subscribed, storing the update in S3, and notifying the upstream processors runner service (PRS) of the update.
- The data access layer service (DAL) is how services access the data stored in S3. Each update is stored as a single, immutable, object in S3 and the DAL is responsible for aggregating the updates into a canonical view of a record at a given point in time. This also serves as the semantic layer on top of S3 by translating data from its at-rest representation — which makes no assumptions about the schema or format of the data — into protobufs, and by defining the join relationships necessary to stitch multiple related records into a data view.
- The processors runner service (PRS) receives these notifications and determines which checks — also known as processors — are applicable to the notification. Before running the check, it calls the data access layer service to fetch the data view required to perform the check.
The Ingestion Service
A predominant design goal of the ingestion service is to support any format of incoming data. As we look to integrate Overseer into all of Coinbase systems in the future, it is crucial that the platform is built to easily and efficiently add new data sources.
Our typical pattern for receiving events from upstream data sources is to tail its database’s WAL (write-ahead log). We chose this approach for a few reasons:
- Coinbase has a small number of database technologies that are considered “paved road”, so by supporting the data format emitted by the WAL, we can make it easy to onboard the majority of our services.
- Tailing the WAL also ensures a high level of data fidelity as we are replicating directly what’s in the database. This eliminates a class of errors which the alternative — to have upstream data sources emit change events at the application level — would expose us to.
The ingestion service is able to support any data format due to how data is stored and later received. When the ingestion service receives an update, it creates two artifacts — the update document and the master document.
- The update document contains the update event exactly as we received it from the upstream source, in its original format (protobuf bytes, JSON, BSON, etc) and adds metadata such as the unique identifier for the record being modified.
- The master document aggregates all of the references found in updates belonging to a single database model. Together, these documents serve as an index Overseer can use to join records together.
When the ingestion service receives an update for a record, it extracts these references and either creates a master document with the references (if the event is an insert event), or updates an existing master document with any new references (if the event is an update event). In other words, ingesting a new data format is just a matter of storing the raw event and extracting its metadata, such as the record identifier, or any references it has to other records.
To achieve this, the ingestion service has the concept of a consumer abstraction. Consumers translate a given input format into the two artifacts we mentioned above and can onboard new data sources, through configuration, to tie the data source to a consumer to use at runtime.
However, this is just one part of the equation. The ability to store arbitrary data is only useful if we can later retrieve it and give it some semantic meaning. This is where the Data Access Layer (DAL) is useful.
DAL, Overseer’s semantic layer
To understand the role played by DAL, let’s examine a typical update event from the perspective of a hypothetical Toy model, which has the schema described below:
type Toy struct {
Type string
Color string
Id string
}We’ll further assume that our Toy model is hosted in a MongoDB collection, such that change events will have the raw format described here. For our example Toy record, we’ve recorded two events, namely an event creating it, and a subsequent update. The first event looks approximately like this, with some irrelevant details or field elided:
{
"_id": "22914ec8-4687-4428-8cab-e0fd21c6b3b6",
"fullDocument": {
"type": "watergun",
"color": "blue",
},
"clusterTime": 1658224073,
}And, the second, like this:
{
"_id": "22914ec8-4687-4428-8cab-e0fd21c6b3b6",
"updateDescription": {
"updatedFields": {
"type": "balloon",
},
},
"clusterTime": 1658224074,
}We mentioned earlier that DAL serves as the semantic layer on top of Overseer’s storage. This means it performs three functions with respect to this data:
Time travel: retrieving the updates belonging to a record up to a given timestamp. In our example, this could mean retrieving either the first or both of these updates.
Aggregation: transforming the updates into a view of the record at a point in time, and serializing this into DAL’s output format, protobufs.
In our case, the updates above can be transformed to describe the record at two points in time, namely after the first update, and after the second update. If we were interested in knowing what the record looked like on creation, we would transform the updates by fetching the first update’s “fullDocument” field. This would result in the following:
proto.Toy{
Type: "watergun",
Id: "22914ec8-4687-4428-8cab-e0fd21c6b3b6",
Color: "blue",
}However, if we wanted to know what the record would look like after the second update, we would instead take the “fullDocument” of the initial update and apply the contents of the “updateDescription” field of subsequent updates. This would yield:
proto.Toy{
Type: "balloon",
Id: "22914ec8-4687-4428-8cab-e0fd21c6b3b6",
Color: "blue",
}This example contains two important insights:
- First, the algorithm required to aggregate updates depends on the input format of the data. Accordingly, DAL encapsulates the aggregation logic for each type of input data, and has aggregators (called “builders”) for all of the formats we support, such as Mongo or Postgres for example.
- Second, aggregating updates is a stateless process. In an earlier version of Overseer, the ingestion service was responsible for generating the latest state of a model in addition to storing the raw update event. This was performant but led to significantly reduced developer velocity, since any errors in our aggregators required a costly backfill to correct.
Exposing data views
Checks running in Overseer operate on arbitrary data views. Depending on the needs of the check being performed, these views can contain a single record or multiple records joined together. In the latter case, DAL provides the ability to identify sibling records by querying the collection of master records built by the ingestion service.
PRS, a platform for running checks
As we mentioned previously, Overseer was designed to be easily extensible, and nowhere is this more important than in the design of the PRS. From the outset, our design goal was to make adding a new check as easy as writing a function, while retaining the flexibility to handle the variety of use cases Overseer was intended to serve.
A check is any function which performs the following two functions:
- It makes assertions when given data. A check can declare which data it needs by accepting a data view provided by DAL as a function argument.
- It specifies an escalation policy: i.e. given a failing assertion, it makes a decision on how to proceed. This could be as simple as emitting a log, or creating an incident in PagerDuty, or performing any other action decided by the owner of the check.
Keeping checks this simple facilitates onboarding — testing is particularly easy as a check is just a function which accepts some inputs and emits some side effects — but requires PRS to handle a lot of complexity automatically. To understand this complexity, it’s helpful to gain an overview of the lifecycle of an update notification inside Overseer. In the architecture overview at the beginning of this post, we saw how updates are stored by the ingestion service in S3 and how the ingestion service emits a notification to PRS via an events topic. Once a message has been received by PRS, it goes through the following flow:
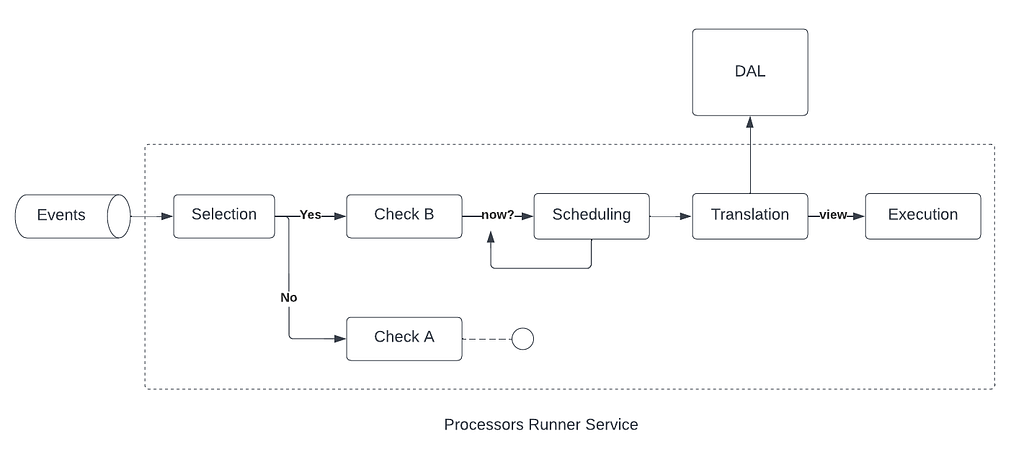
- Selection: PRS determines which checks should be triggered by the given event.
- Scheduling: PRS determines when and how a check should be scheduled. This happens via what we call “execution strategies”. These can come in various forms, but basic execution strategies might execute a check immediately (i.e. do nothing), or delay a check by a fixed amount of time, which can be useful for enforcing SLAs. The default execution strategy is more complex. It drives down the rate of false negatives by determining the relative freshness of the data sources that Overseer listens to, and may choose to delay a check — thus sacrificing a little bit of our TTD — to allow lagging sources to catch up.
- Translation maps the event received to a specific data view required by the check. During this step, PRS queries the DAL to fetch the records needed to perform the check.
- Finally, execution, which calls the check code.
Checks are registered with the framework through a lightweight domain-specific language (DSL). This DSL makes it possible to register a check in a single line of code, with sensible defaults specifying the behavior in terms of what should trigger a check (the selection stage), how to schedule a check, and what view it requires (the translation stage). For more advanced use cases, the DSL also acts as an escape hatch by allowing users to customize the behavior of their check at each of these stages.
Today, Overseer processes more than 30,000 messages per second, and supports four separate use cases in production, with a goal to add two more by the end of Q3. This is a significant milestone for the project which has been in incubation for more than a year, and required overcoming a number of technical challenges, and multiple changes to Overseer’s architecture.
This project has been a true team effort, and would not have been possible without the help and support of the Financial Hub product and engineering leadership, and members of the Financial Hub Transfers and Transaction Intelligence teams.
Real-time reconciliation with Overseer was originally published in The Coinbase Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.

You can get bonuses upto $100 FREE BONUS when you:
💰 Install these recommended apps:
💲 SocialGood - 100% Crypto Back on Everyday Shopping
💲 xPortal - The DeFi For The Next Billion
💲 CryptoTab Browser - Lightweight, fast, and ready to mine!
💰 Register on these recommended exchanges:
🟡 Binance🟡 Bitfinex🟡 Bitmart🟡 Bittrex🟡 Bitget
🟡 CoinEx🟡 Crypto.com🟡 Gate.io🟡 Huobi🟡 Kucoin.




















Comments